Aerospace engineer with a 15+ year career in policy & government. Passionate about numbers and technology. Looking out for a new challenge in the domains of data science, machine learning, and AI.
Strong analytical and problem-solving skills, excellent interpersonal and communication abilities, and accustomed to working in a high-pressure environment. Flexible and a fast learner. And last but not least, immensely motivated to dive headfirst into the ‘brave’ new world of data.
Predictive time series model on Naming Trends in Belgium
Check out code on GitHub
I downloaded CSV files containing first-name data from Statbel, the Belgian statistical office. These files include all newborn names with a frequency of five or more, with separate datasets for boys and girls, covering each year from 1995 to 2023.
Upon performing data cleaning and organization on the year tables, I merged them into one, with a column for each year. I then constructed a time series forecasting model for each name. To capture long-term trends and seasonality, I incorporated polynomial and Fourier terms. For short-term fluctuations and variability, I added lag terms. Additionally, I used XGBoost to model residual errors, though I found it led to overfitting for some names.
I trained the model on data from 1995 to 2020 and validated it using the 2021–2023 period. To optimize the model for each name, I performed a grid search to determine the best polynomial degree, number of Fourier and lag terms, and whether to include error modeling. The model achieved a strong fit, with a median RMSE of 2.858 for girls' names and 3.367 for boys' names.
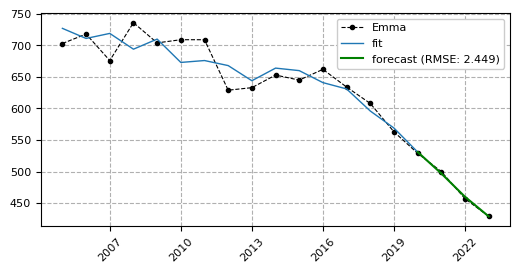
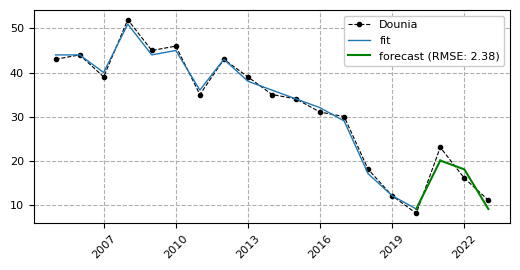
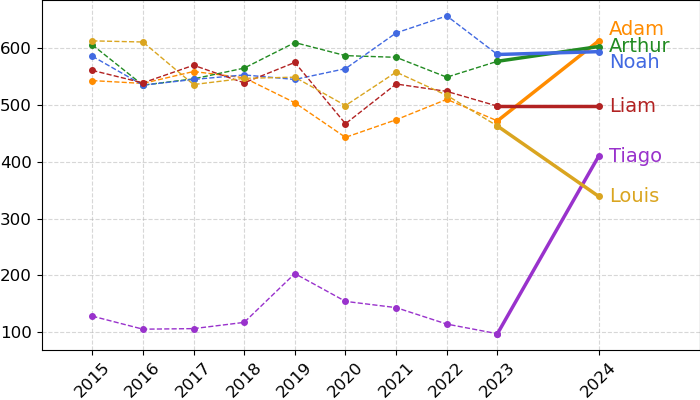
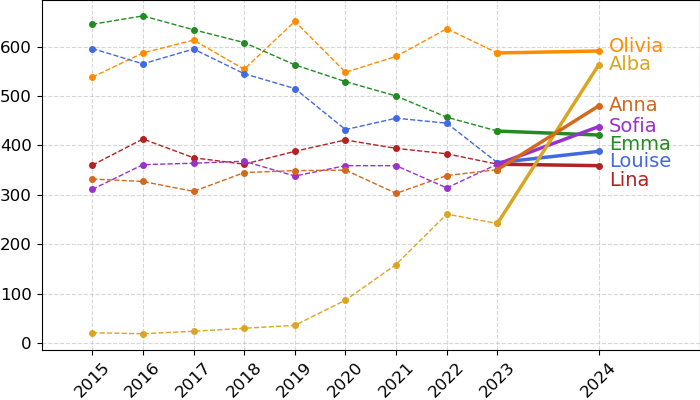
According to the forecasts, 2024 will bring some interesting shifts in the Top 5 names! Olivia will remain the most popular girls' name, while Alba will see a surge in popularity, reaching second place. In the boys' category, a new leader will emerge — Adam will jump from fourth to first place. Meanwhile, Louis will drop out of the Top 5, making way for Tiago. Now we'll just have to wait patiently for the 2024 data to be released...
Kaggle competition: Binary Prediction with a Rainfall Dataset
Check out code on Kaggle
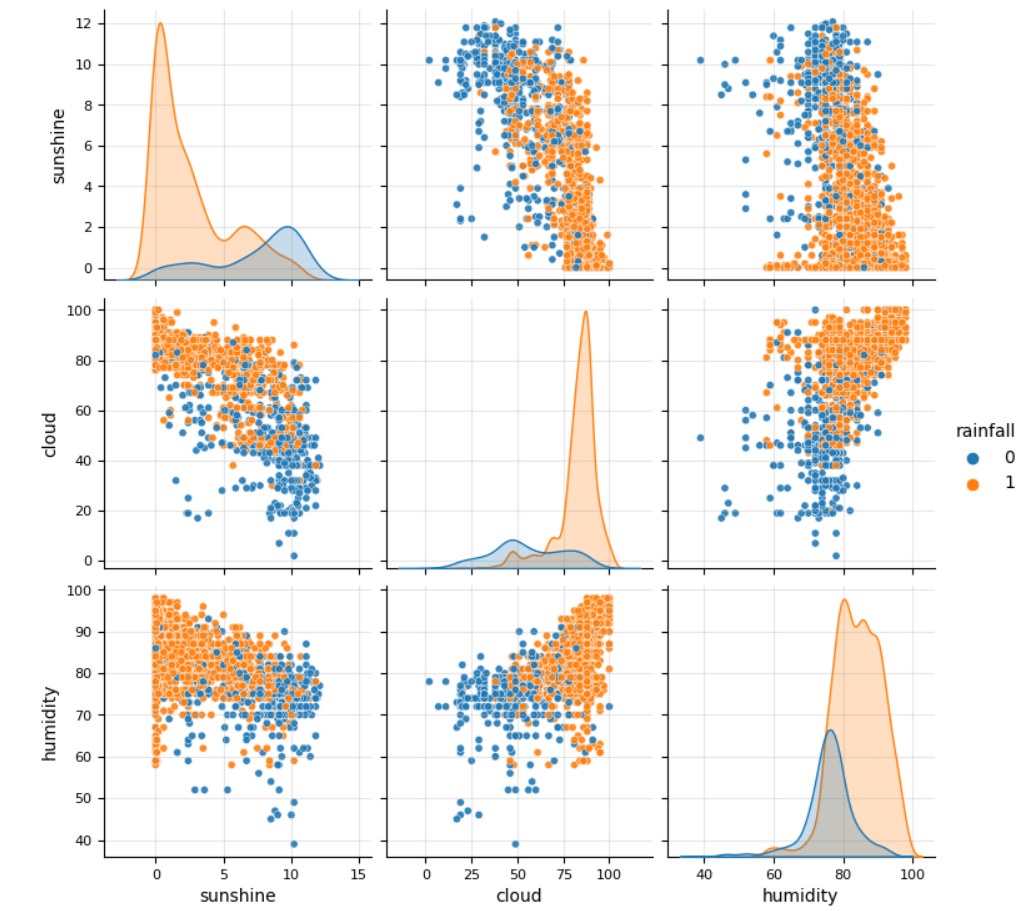
The goal of this competition was to predict rainfall based on meteorological parameters such as temperature, dewpoint, pressure and windspeed. Submissions were evaluated using the area under the ROC curve (AUC). My model achieved a test score of 0.89890, ranking 438th out of 4,381 submissions.
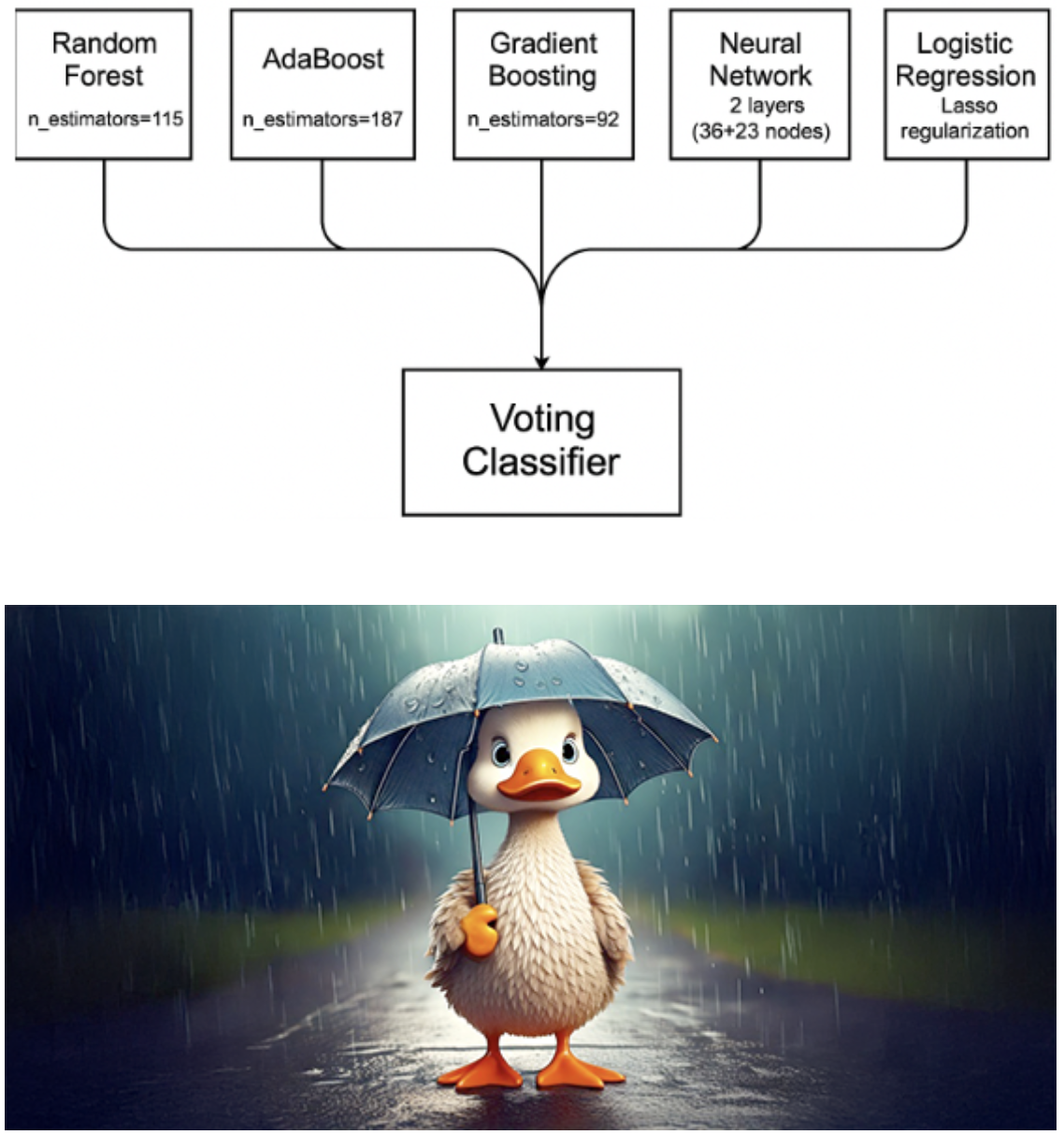
I began with exploratory data analysis (EDA), which highlighted the significance of humidity, cloud cover, and sunshine as key features. Next, I explored multiple machine learning models, using the Optuna framework for hyperparameter optimization. Finally, I built a voting model as an ensemble learner, combining predictions from individual base models to improve overall performance.
Python exercise: Sudoku Solver
Check out code on GitHub
Not exactly data science, but a great exercise in logical thinking, Python programming, and even a fair bit of HTML! I developed a Python script to solve Sudoku puzzles and built a Sudoku Solver website, allowing anyone to try it out.
Having a hard time with your Sudoku? Check out the website and solve it here!